Honey | [Outdated] Tutorial
Introduction
Honey is a small but high level, flow oriented, declarative programming language designed to facilitate the pre-processing and analysis of symbolic and numerical time series and sequence datasets.
A script is a text file with the ".tit" extension. A script defines a list of operations to apply on a dataset (or a set of datasets). Each line defines one operation to apply on the dataset. Each operation takes one or several input signals, and produces one or several output signals. You will see that some operations do not require any input (e.g. the calendar change point generation operation, reading of keyboard) and some other do not produce any signal output (e.g. the write to file operation, printing on screen).
Opposite to most programming languages, Honey does not have conditional and loop keywords. A script defines a flow of operations. Each operation processes its input, and produces some output that will be sent to some other operations. Instead of IF statements, Honey has several operations which filter data. It might seem strange, but you will see that it makes the scripting very clear. Additionally, due to this structure, a script can be seamlessly applied on a static dataset or on an online/continuous data flow.
While Honey has its own particular syntax (that you will lean in this tutorial), you can use any editor configured with the Perl syntax coloration to help in Honey script reading.
Honey supposes input and output datasets to be Symbolic and Scalar Time Sequence (SSTS). A SSTS is composed of channels. Each channel is associated with a name (also called channel symbol) and a set of records. Each record is associated with a timestamp (represented as a double precision floating point number) and a value (represented as a single precision floating point number).
The following table shows an example of SSTS with three channels. Each record is represented by (x,y) where x is the time-stamp and y is the value.
| Symbol | Records |
|---|---|
| e1 | (15.81,1) (16,1) |
| s1 | (5.,-5.1) (20.,5.2) (28,12) (28,13) |
| s2 | (1.,1.1) (2.,1.1) (5.81,12) (12,-1) |
Each SSTS channel is either an event or a scalar. Both types are stored similarly and only differ in the way the user wants to interpret them. Events generally represent change-points, while scalars generally represent regularly (or semi-regularly) sampled measurements. We will also talk about status channels. A status channel is a scalar channel that can only have the value 0 or 1.
SSTS can be represented graphically (see figure 1).
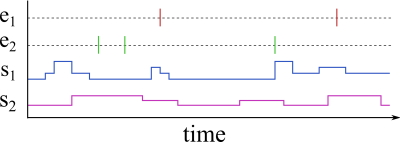
You might be familiar with multi-variate time series. This well-known representation is a special case of SSTS. Therefore, Honey can be used to process multi-variate time series.
SSTS are used to represent a large variety of phenomena. For example, an event channel can be used to indicate the purchase of an item, the activation of a sensor, or the start of a new day. Similarly, a scalar channel can be used to count the number of purchases of an item in the last 2 hours, the current temperature, or the numerical value of the current hour.
The simplest and most used file format to store time series is certainly the CSV format. A .csv file is a text file that represent a two dimensional array. The first column of the array contains a list of timestamps while the other columns contain the numerical values of the different scalar channels for each timestamp.
The .csv format is very convenient to store and exchange datasets; It is simple to write and read, and it is supported by many versions of software. However, .csv files require all channels to be synchronized, and reading/writing to .csv is a slow operation, in comparison to more optimized binary formats. While CSV is a good first candidate, this tutorial also present several other formats supported by Event Script.
Running a script
To execute a script, the Honey binary should be executed with the path to the script file as first argument. The file path of the input dataset is optional and can be specified with the "--input" argument. An empty file is acceptable.
Several "--input" arguments can be provided in a single call. In this case, all the input will be merged together before the script is applied.
The output are specified inside of the script (with the operator "save" for example). However, we will see later how to specify the output path from the command line using variables.
The "--graph" option is a very useful option for Honey to generate a PNG picture, graphically representing the script. GraphViz (http://www.graphviz.org/) needs to be installed on your computer to use this option. This feature is very useful to read and understand large scripts. The following figure shows the graphical representation of a script. You do not have to try to understand the script right now.
|
Example of script
$A = echo "price"
$A += sma $A 10 $A += sma $A 20 |
Becomes |
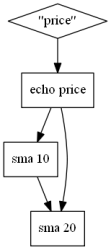
|
If you use the honey script editor included with Event Viewer, you will see the script graph representation on the right of your script:
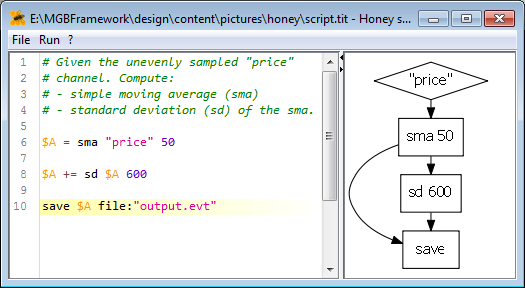
Looking at the result
During the writing of a complex script, it is advised to look and plot the intermediate and final results to ensure of the correctness of the script. Many plotting softwares are available for this task (e.g. GnuPlot, R, R+ggplot, Matlab, Python+Matplotlib, etc.). We however recommend the use of the Event Viewer software available here.
Here are some of the many features that make Event Viewer a good candidate to visualize Honey results:
- Event Viewer supports all output formats of Honey (event the binary format).
- It can load and display very large datasets (in comparison to other plotting software).
- It allows simple and efficient data "navigation" with the mouse (zooms, translation, anchor, etc.).
- Event Viewer's display is highly configurable.
- Only one-click is necessary reload the result of a script.
Comments
Each empty line or line starting with the character, "#", is considered a comment and will not be executed.
Line syntax
Each (non-comment) line is composed of an operator name followed by a list of anonymous arguments for the operator, followed by a list of named arguments.
derivative "price"
# A command with two anonymous arguments
sma "price" 50
# A command with two anonymous arguments and a named argument
sma "price" 50 trigger:"alert"
Depending on the operators, some anonymous/named arguments can be optional. If they are not specified, they will be assigned to a default value.
Named arguments can be specified in any order. However the order of the anonymous arguments is important.
Honey allows two types of arguments.
- A signal argument takes a single (or a list of) channels.
- A non-signal argument takes a string or numerical value.
sma "price" 50
The sma operator accepts two anonymous arguments. The first one is a signal argument. The second one is a non-signal numerical argument.
The quotations around arguments are optional. They are mostly useful when argument names contain spaces.
sma "price" 50
sma price 50
sma price "50"
Operations as well as their arguments are described in the Function reference.
Signal variables
Honey supports two types of variables
- A signal variable (starting with $) contains a list of named channels.
- A non-signal variable (starting with %) is either a string or a numerical value.
Signal variables are used to connect operations together. Signal variables can be seen as "pipes": On one side, one or several operations put signals into the pipe. On the other side, other operations continuously will get from these signals. While not entirely accurate, a signal variable can be seen as a container of signal for static script execution: Some operations put signal in a variable. Next, other operations will take and process these signals.
Piping the result of an operation into a variable is done with the "=" keyword.
$A = sma "price" 50
The result of an operator can also be aggregated to a signal variable with the operator "+=".
$A = sma "price" 50
$A += sma "price" 100
At the end of the previous example, $A contains two channels: the result of the two "sma's". Note: the two "sma's" results are not numerically added together.
$A = sma "price" 50
$B = ema $A 10
When supplied with a list of channels, most operations will be applied independently on each channels.
Non-signal variables
Non-signal variables are used to store non-signal arguments.
Setting a non-signal variable is done with the "set" operator.
$A = sma "price" %window
Non-signal variables can be defined through the command line with the "--option" argument.
Passing non-signal variable with "--option" keyword can be used to specify the path of the output files in the command line.
Save $result file:%output
*Command line*
honey my_script.txt --input "input.evt" --option output:"output.evt"
Polish Notation Equations
Non-signal arguments can be specified by an equation in Polish notation. Numerical Polish notation equations start with "=". String Polish notation equations start with "&".
sma "price" 30
sma "price" =10,3,*
# The next following two lines are equivalent
save "price" file:"output.evt"
save "price" file:&output,.evt,+
Available numerical operators are: +, *, -, /, >, <,=, ^,>=, <=, !=, if, sin, cos, tan, log, rand, asin, acos, atan and sqrt. Available string operators are: +.
Honey supports Polish Notation for both specifying arguments value, but also to define operations on signal (see "eq" and "passIf" operations)
Non-tailing operators
Honey operators are tailing operators. In other word, not operators can return at time t, a value computed with data from t' with t' > t.
The only exception to this rule is the "echoPast" that can "send data in the past". Note that the echoPast function does not work in online streaming execution.
This constraint ensures that a script runs the same way both online or on completed data.
Channel naming
Each channel of a SSTS is attached to a name. Different variables can contain a same channel, and different variables can contains different channels with the same name.
The result of most operators is returned as a channel or a list of channels. The names of the result channels are automatically generated according the input channel names, operator name and operator arguments.
For example, the result of applying the sma operator with a parameter of 30 time units on the channel "price" will be named "price_sma[30]".
Generated names generally have the following structure: {original channel name}_{operator name}[{argument values}].
Channel names can be changed with the "rename" and "renameRegexp" operators.
The "rename" operator changes the name of a channel (or a list of channels) to a new given name.
$A = sma "price" 30
$A = rename $A "toto"
Note that if several channels are provided as input, an error will be raised. However, if the option "keepAll:true" is specified, no error will be raised and all the input channels will be merged together.
RenameRegexp changes the name of a channel (or a list of channel) to a new name defined by a string replacement regular expression.
$A = echo "price_corn"
$A += echo "price_tomato"
$A += echo "price_orange"
# Compute the sma for each of the three channels.
$B = sma $A
# Rename the results of the sma from "price_corn_sma[30]", "price_tomato_sma[30]" and "price_orange_sma[30]" to "30_toto_corn", "30_toto_tomato" and "30_toto_orange".
$C = renameRegexp $B "price_([a-z]+)_sma\[(0-9)+\]" "$2_toto_$1"
The most useful operators
The most basic (and useful) operators are: echo, print, sma, filter, save and saveBufferedCsv.
Echo
Echo just repeats a signal (or a set of signals). It is mostly used to branch "pipes" together. Echo is also generally use at the beginning of a script to "catch" channels by their name, and put them into pipes. Finally, if echo's argument starts with the character #, the argument is considered as a regular expression applied on all available channels in memory. In this way, a single echo can be used to capture several (or all) channels. To avoid infinite cycles in pipes, it is generally recommended to use echo at the beginning of the script in order to catch all the input signals into a single variable, and then to use this variable in the script.
$A += echo "#price_.*"
$B = echo $A
# Select all the channels in memory (so far) -- this can generate duplicates.
$ALL = echo #.*
"Print" displays (in the console) the name and statistics of the time sequences inside of a signal variable. An optional label argument allows to "label" the output. If every:true, all of the events of the time sequence are individually printed.
print $A label:"The content of the variable $A"
print $A every:true
Filter
Filters the channels coming from a signal variable with a regular expression.
$A += echo "amount"
# $A contains "price" and "amount"
$B = filter $A "p.*"
# $B only contains "price"
# The two following lines are equivalent
$A = echo #[0-9]*
$A = filter #.* [0-9]*
sma (simple moving average)
Sma computes a tailing simple moving average.
Sma has two additional optional parameters.
- minNumObs (default value of 6) defines the minimum number of observations allowed to compute the moving average. If less than this number of observations are available, no result will be returned.
- trigger takes as input a signal and will force the sma operator to only compute an output when a trigger signal is provided. By default, the sma operator produces a new output whenever it receives an input.
SaveBufferedCsv
SaveBufferedCsv saves the content of a signal variable to a CSV file.
Note that if all channels are not synchronized, the csv will be filled with "NA" values. Additionally, since all channel names need to be available to write the csv header, this operation will keep a full copy of the exported data in memory until the end of the script execution where the csv file is written.
Save
Saves the content of a signal variable to a Evt file.
Unlike saveBufferedCSV, save writes immediately the signal in the file, and remove it from memory.
Input and output file format
Honey support four dataset formats.
CSV format
A .csv file is a text file that represent a two dimensional matrix. The first column contains timestamps while the other columns contain the numerical values of the different channels for each timestamps.
0 10 11
2 10.5 11.1
3.1 10.4 NA
CSV requires all the channels to be synchronized.
EVT format
A .evt file is a text file where each line specifies an event or scalar update. Each line is {time stamp} {signal name} {signal value}.
0 price_apple 11
2 price_orange 10.5
2 price_apple 11.1
EVT format is especially useful when channels are not synchronized.
1 price_apple 5
1.1 price_orange 11.1
5.2 price_apple 2
BIN format
A .bin file is a compact binary encoding of a .evt file. The binary format is faster to read and write than the EVT and CSV formats. For this reason, the binary format is preferable in large datasets. Like the EVT format, the bin format handles naturally non-synchronized channels.
SEVT format
An .sevt is a text file containing paths to other datasets files.
dataset dataset2.csv
dataset dataset3.evt
flush true
The "dataset" commands accept three options. The first option is the path to the dataset. The second option (optional) is a prefix to add to each channel names. The last option (also optional) is a regular expression to filter the channel to load in memory
dataset dataset2.csv prefix2.
dataset dataset3.evt prefix3. (dog|cat)_.*
flush true
If several groups of datasets are separated by the "flush" command, the dataset times will be shifted so that different groups do not overlap. The "sequence" options allows you to define the channels "sequence" and "end_sequence" that will be set at the beginning and end of each group. The time distance between groups is defined with the "minoffset" options. Note that if the dataset contains several "groups", you should use "flush" instead of "flush true".
sequence 1
dataset group1_dataset1.csv
dataset group1_dataset2.csv
flush
sequence 2
dataset group2_dataset1.csv
dataset group2_dataset2.csv
flush
By default, dataset path are relative to the current directory of the running process.
The .sevt format supports many more options that will be described later. Instead, you can specify for the path to be relative to the .sevt file path with the option "basepath relative".
dataset dataset.csv
flush
You can also specify dataset records in the .sevt file itself with the "event" command. This feature should be reserved to load structural events. The syntax is "event {time} {symbol} {value}". Note that the time will be shifted the same way at the datasets from the "dataset" command. The time can also be the string "begin" or "end". In this case, the time value is set for the event to be the first (or the last) event between the previous and next "flush" commands.
minoffset 3600
sequence 1
dataset group1_dataset1.csv
dataset group1_dataset2.csv
event 0 this_is_at_time_0 1
event begin this_is_the_beginning_of_sequence_1 1
event end this_is_the_end_of_sequence_1 1
flush
sequence 2
dataset group2_dataset1.csv
dataset group2_dataset2.csv
event begin this_is_the_beginning_of_sequence_2 1
event end this_is_the_end_of_sequence_2 1
flush
Alternative input dataset definition
By default, the input datasets are defined through the command line with the "--input" options. Symmetrically, the output datasets are defined in the script with the saving operators. To clarify the script, the user can also specify the input and output dataset at the beginning of the script with the "AUTODATASET" operator. Autodataset also allows applying script on directories. In this case, the script will be applied iteratively on each file of the directories, and the result for each file will be saved in a separate file. The path of the output file will be automatically put into the %output non-signal variable.
AUTODATASET requires three named options (the last one is optional).
- Input: Define the input file path or input directory path.
- Output: Define the output file path or output directory path.
- Extension: Define the output extension in Output is a directory.
save $B file:%output
save $B file:%output
Handling entities
Many datasets contain an "entity" structure. Such datasets are composed of several SSTS, each of them describing a same phenomenon for different entities. As an example, we can suppose a dataset about cars where, for each car, the dataset contains a record of actions (getting fuel, go to the repair shop). In this dataset, cars are "entities".
Honey can handle entity datasets in two ways. Depending on the dataset, one way is generally obviously preferable to the other.
The first way is to treat each entity independently. In this case, the dataset of each entity should be located in a separate file all in a same directory. Then, Honey can be used with this directory as input. In this configuration, each file/entity will be treated one-by-one and independently.
This solution is useful when there are not interactions between entities, if the number of entities is small (e.g. less than 10000) and if the dataset of each entity is large.
The second solution is to glue the record of all the entities one after the other. This can be done automatically using the .sevt format and the "sequence" key word. A special symbol can be used to indicate the separation between entities.
This last solution is very efficient, especially for sparse datasets containing a large number of entities. It also allows both to perform analysis for each entity, and for all the entities together.
The following example shows how to use the second method to create a .csv file that will contain for each entities the number of record and the mean of the signals A, B and C.
minoffset 1000
sequence 1
dataset entity_1.csv
flush
sequence 2
dataset entity_2.csv
flush
$ALL = echo #.*
$END_OF_ENTITY = filter $ALL "sequence_end"
$SIGNALS = filter $ALL (A|B|C)
$RESULT = count $SIGNALS 1000 trigger:$END_OF_ENTITY
$RESULT += sma $SIGNALS 1000 trigger:$END_OF_ENTITY
$RESULT += echo $END_OF_ENTITY
saveBufferedCsv $RESULT file:%output
Report operators
Most operators consume data and produce output in a greedy fashion (e.g. sma, sd). Some other operators (called "report" operators) only output data at the end of the script execution. These operators generally compute metrics about the entire dataset. These operators can return any type of data (.csv file, text, pictures, etc.). These operators can generally only be applied in static mode. Their names start with "report_" e.g. "report_implication". If a report operator returns data other than in the SSTS format, it has an argument for the user to specify the output file.
Example of such operators are:
-
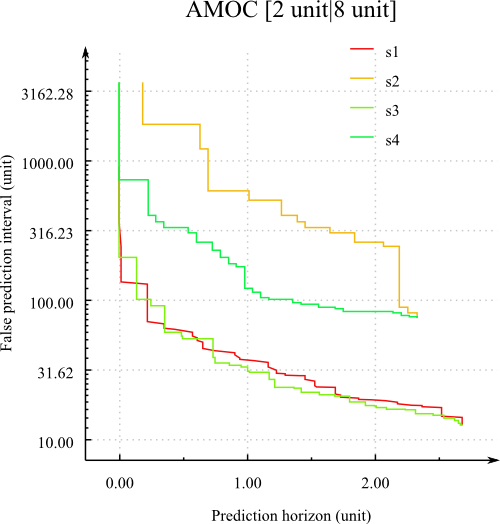
report_amoc : Compute the AMOC and Temporal ROC between a trigger signal and a target signal.
It also compute various "snap-shots".
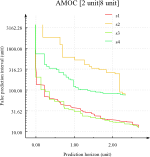 Example of AMOC
Example of AMOC -
report_histIntersectEventState : Compute the distribution of a set of state variables sampled
according to a set of events.
 Example of histIntersectEventState report
Example of histIntersectEventState report - report_histIntersectEventScalar : Compute the distribution of a set of scalars sampled according to a set of events.
Running modes
Honey can be executed in three possible modes: Static, streaming and real-time streaming. The mode can be specified by the "--mode" command line option. By default, the mode is set to STATIC.
The static mode (default) loads all the input dataset in memory, and applies each operation one after one another. Intermediate results of operations are automatically discarded during the script execution as soon as the algorithm detects that it will not be used anymore. Because each operation is applied one after another, the static mode is very quick. The static mode is however not suited if the dataset is too large to be loaded in memory.
The streaming mode greedily reads and processes a dataset input file line by line. This process is much slower that the static mode, but it has very small memory consumption. For example, if applying of 10s moving average on a signal using the streaming mode, at most 10s of signal will be kept in memory at any time.
Finally, the real-time streaming mode works similarly to the streaming mode, but override the timestamps with current computer clock value. This mode is suitable for real-time online analysis.
As an example, suppose the following program that will be executed in static and streaming mode.
$A = sma "price" 10
$B = derivative $A
Save $B file:output.evt
Static execution
- The dataset is loaded in memory
- The "price" channel is selected, and a moving average is applied.
- The derivative operator is applied on the moving average results.
- The moving average is removed from memory because it will be not used anymore.
- The result of the derivative is saved in the output.evt file.
- The derivative results are fed from memory.
Streaming execution
- The first line of the dataset is read as an event.
- This first event is sent to the sma operator, who stores it and produces a result.
- The results of the sma operator is sent to the derivative operator.
- The result of the derivative operator is saved to the output.evt file
- The second line of the dataset is read as an event.
- ...
Pseudo-flow programming
While the execution of Honey is done in flow, the parsing of the script file is interpreted sequentially. Therefore, a single signal variable is not exactly equivalent to a single pipe.
This concept is illustrated in the following example :
$A += sma $A 10
$A += sma $A 20
In this script, the variable $A refers to different flow pipes after each line of the script.
At the end of the script, $A contains "price", "price_sma[10]","price_sma[20]","price_sma[10]_sma[20]".
This script is represented graphically by: